On context switching and C programs in userland
 In the last post, I discussed how I implemented collaborative execution in SnowflakeOS through the
In the last post, I discussed how I implemented collaborative execution in SnowflakeOS through the iret instruction. Well, at that time the implementation wasn’t finished, even though I thought it was: I wasn’t restoring general purpose registers. This led to some pretty nice bugs, as pictured above.
Context switching
I noticed that issue and at first decided to tackle it my own way, moving the contents of my registers_t structure to the corresponding registers, but it proved a bit difficult. It would have been doable with more thought, but instead I searched the internet for the “usual” way to restore context.
It turns out there’s a very elegant way to do it: instead of using iret everytime, simply switch stack and let the execution get back to the interrupt handler by just letting execution reach the end of the function.
This works because the stack state of every interrupted process is the same when getting to the stack-switching part of execution: what we do is simply pop registers from the next process’s stack, not the one that was last interrupted.
For now the subroutine is implemented in assembly as I mainly copied it from a wiki page but I should be able to turn it into C no problem, contrary to what the page says. Here’s the current code:
proc_switch_process: # void proc_switch_process();
# Save register state
push %ebx
push %esi
push %edi
push %ebp
# current_process->esp = %esp
mov current_process, %eax
mov %esp, 24(%eax)
# %eax = current_process = current_process->next
mov (%eax), %eax
mov %eax, current_process
# Set esp0 to the next process's kernel stack in the TSS
push %eax
push 20(%eax) # kernel_stack
call gdt_set_kernel_stack
add $4, %esp
pop %eax
# Switch to the next process's kernel stack
mov 24(%eax), %esp
# Switch page directory
mov 16(%eax), %ebx # directory
mov %ebx, %cr3
# Restore registers from the next process's kernel stack
pop %ebp
pop %edi
pop %esi
pop %ebx
ret
That leaves the problem of how to switch to tasks which haven’t been started yet, and thus haven’t had the chance to be interrupted: we can’t switch to their kernel stack to restore the process’s context, there’s nothing there. I haven’t thought this through, but I don’t think we can iret manually a second time, we’d mess up the kernel stack of the currently executing process.
I opted for the solution of setting up that stack manually in proc_run_code. It’s ugly (see for yourselves), but hey, it works. I’ll make something nicer at some point, I haven’t researched how it’s usually done.
Implementing preemptive multitasking, i.e. interrupting and resuming tasks without asking them was then simply a matter of calling proc_switch_context from my timer interrupt handler.
If you look at the commit implementing all this, here, you’ll notice that I’m not calling iret when first entering usermode. And yet the code seemed to work, and it in fact sort of did! By a miracle of chance, the ret instruction for the function proc_enter_usermode popped the pushed eip = 0 from my inline assembly, thereby calling my process code. Of course with a simple ret the execution was still in ring 0, but on subsequent switches, everything was as right as ever.
Ongoing code documentation
Understanding and debugging that new context-switching method took me quite a while and led me to improve my interrupt code. It’s now pretty well documented, see for instance isr.S or gdt.h. I had several misunderstandings in that area of the code, notably differences between ISRs and IRQs, their relation with the IDT and the GDT… Now it’s all good.
Quick explanation. The IDT is a table that stores pointers to interrupt handlers along with details like which code segment to use when switching execution to the handler, etc… ISRs are one type of interrupts, numbered from 0 to 32 and also called “exceptions”, and IRQs are another, numbered from 32 to 47, also called “hardware exceptions”. The GDT describes memory segments referred to in the IDT.
It’s interesting to note that the IDT and GDT have very similar structures, and that both are particularly horrid. For instance, the address of the start of a memory segment is split into three non-contiguous parts in a GDT entry: two of 8 bits and one of 16. Crazy stuff.
Rebuilding the build system
SnowflakeOS $ time make SnowflakeOS.iso
[...]
real 0m1,140s
user 0m0,733s
sys 0m0,347s
With such progess in my userland, I now had to have a straightforward way of building programs. At first I hacked my libc’s Makefile to build C programs and link them with libc. I don’t know exactly what was wrong, but I couldn’t get GCC to compile them to flat binaries. I then looked into making an ELF loader, but it looked difficult to get right. Then I decided it was time to simplify my build system and do things correctly.
I replaced my interdependent shell scripts with a simple Makefile combining all of their functionalities. It would now be pretty easy to automate the whole cross-compiler toolchain building phase in there too.
The build process is still fundamentaly the exact same: first headers are copied to a fakeroot environment, then code is compiled per-project (a project being the kernel, the libc and modules, for now) using the system headers from the fakeroot directory.
There’s a slight problem as this Makefile relies on the order of compilation of projects which isn’t specified very strictly, so running make -j (parallel compilation) will cause errors.
After that, I managed to get module compilation in working order.
Userland programs as GRUB modules
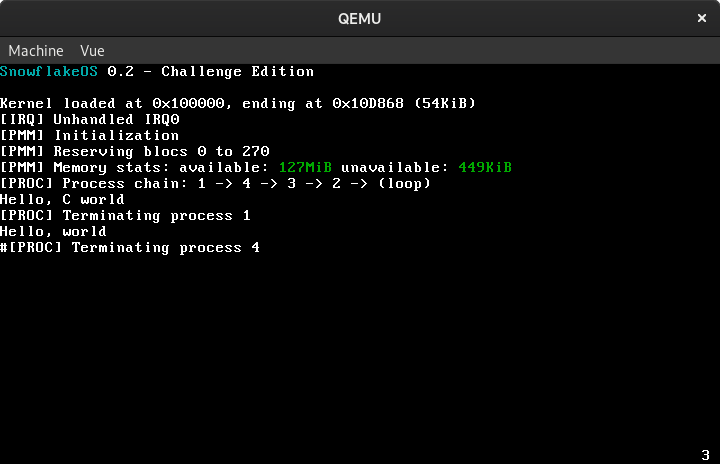
Notice the “Hello, C world” line on here? That’s a usermode process calling my libc’s printf implementation, which itself uses my putchar system call to print characters:
int putchar(int c) {
#ifdef _KERNEL_
term_putchar(c);
#else
asm (
"mov $3, %%eax\n"
"mov %[c], %%ebx\n"
"int $0x30\n"
:
: [c] "r" (c)
: "%eax"
);
#endif
return c;
}
At the bottom right of the screenshot is the currently executing process. Also, notice how I sneakily increased the version number when writing this article :)
There’s one peculiar thing at play here worth noting: I thought it good to follow the advice from here, to have an assembly prologue to call main in my C programs and to call exit with main’s return value. And to push main’s arguments too, in the future. But I couldn’t get GCC to put my prologue code at the entry point: it always, always places a call to main as the first instruction, then a few nops, and only then my prologue, which of course is more of an epilogue at this point.
It’s enough to call exit, and I guess if I really want my argc and argv I’ll set up the process stack myself, I’ve done that before ;)